Instantly know what's human and AI on Twitter, LinkedIn, Substack and more. Get our new Chrome extension.
AI Conference Papers are Increasingly Being Written by AI: up 370% since 2023
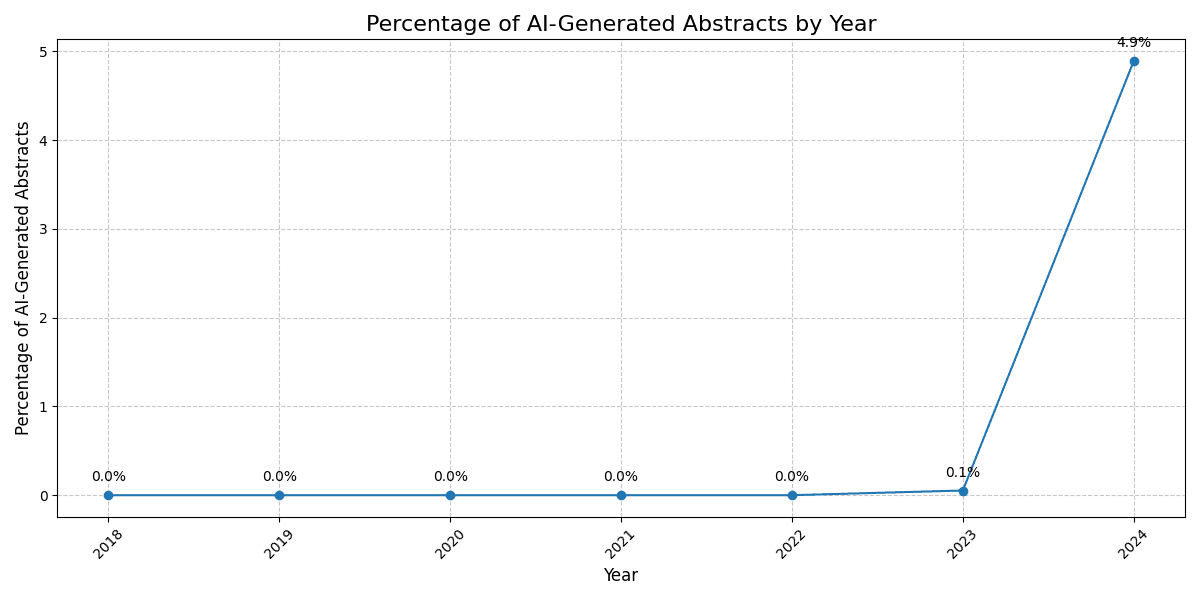 A chart depicting the percentage of AI-generated abstracts submitted to ICLR by year, revealing an upward trend since 2023.
A chart depicting the percentage of AI-generated abstracts submitted to ICLR by year, revealing an upward trend since 2023.
In February 2024, an article published in Frontiers in Cell and Developmental Biology featured figures that were obviously AI-generated. This particular article made headlines as one of the images featured a rat with absurdly large testicles and gibberish text that made absolutely no sense.
This is a real paper published in Frontiers in Cell and Developmental Biology. The figures are obviously AI generated. One of them features a rat with absurdly large testicles. The text in the figures is gibberish. pic.twitter.com/4Acn2YZYwM
— Cliff Swan (@cliff_swan) February 15, 2024
While peer review (in theory) should be good enough to catch obvious cases like this, what about when the actual content of the paper is AI-generated? Even experts have trouble telling AI-generated research apart from human-written research.
A recent Nature news report highlights the growing concern about AI-generated content in academic papers. The article discusses a study where computer scientists used Claude 3.5, one of the latest LLMs, to generate research ideas and write papers, which were then presented to scientific reviewers. These reviewers then rated the papers on "novelty, excitement, feasability, and expected effectiveness". On average, it was found that the reviewers scored the AI papers higher than the human written papers! This leads to the question, does AI actually come up with better research ideas than humans? While tempting to believe that this might be the case, of the 4,000 AI-generated papers studied by the researchers, only 200 of them (5%) actually contained any original idea: most of the papers simply were regurgitating already existing ideas from the LLM's training set.
Ultimately, AI-generated research hurts the community by adding noise and reducing signal in the peer review process, not to mention wasting the time and effort of the reviewers that take care to uphold the standards of research. Furthermore, what's even worse is that AI-generated research often seems convincing, but in actuality, the text produced by a language model just sounds fluent, and may be riddled with errors, hallucinations, and logical inconsistencies. The concern here is that even expert reviewers often cannot even tell when what they are reading is an LLM hallucination.
The organizers of the major machine learning conferences agree with us: there is no place for LLM-generated text in scientific writing. The official policy for ICML (International Conference on Machine Learning) is as follows:
Clarification on Large Language Model Policy
We (Program Chairs) have included the following statement in the Call for Papers for ICML represented by 2023:
Papers that include text generated from a large-scale language model (LLM) such as ChatGPT are prohibited unless the produced text is presented as a part of the paper’s experimental analysis.
This statement has raised a number of questions from potential authors and led some to proactively reach out to us. We appreciate your feedback and comments and would like to clarify further the intention behind this statement and how we plan to implement this policy for ICML 2023.
TLDR;
The Large Language Model (LLM) policy for ICML 2023 prohibits text produced entirely by LLMs (i.e., “generated”). This does not prohibit authors from using LLMs for editing or polishing author-written text. The LLM policy is largely predicated on the principle of being conservative with respect to guarding against potential issues of using LLMs, including plagiarism.
Despite this warning, we find that a significant and growing number of authors in the machine learning field are violating the policy and using AI to generate text in their papers anyway.
Measuring the scope of the problem
At Pangram, we wanted to measure the scope of this problem in our own field: Artificial Intelligence. We set out to answer the question: are AI researchers using ChatGPT to write their own research?
To study this problem, we used the OpenReview API to extract conference submissions from 2018 to 2024 at two of the largest AI conferences: ICLR and NeurIPS.
We then ran Pangram's AI Detector on all of the abstracts submitted to these conferences. Here are our findings:
ICLR
A chart depicting the percentage of AI-generated abstracts submitted to ICLR by year, revealing an upward trend since 2023.
NeurIPS
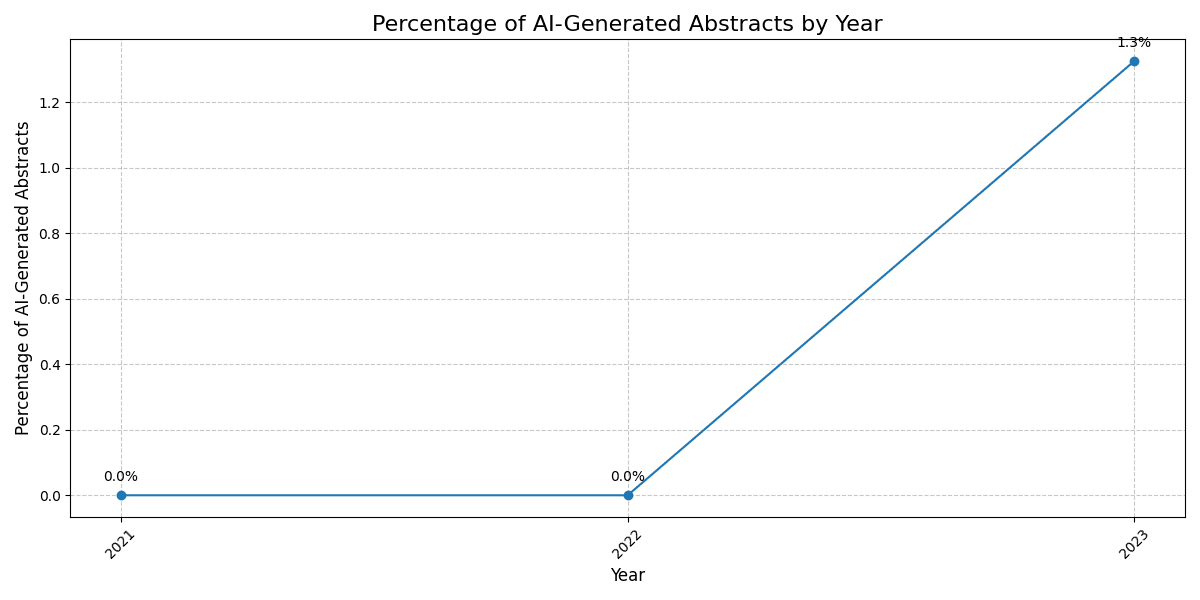 A chart depicting the percentage of AI-generated abstracts submitted to Neurips by year, revealing an upward trend since 2023.
A chart depicting the percentage of AI-generated abstracts submitted to Neurips by year, revealing an upward trend since 2023.
The Results
We can view everything before 2022 as a validation set on the false positive rate of our model, because large language models didn't exist back then. As shown in the figures, we predict that every single conference abstract from 2022 or before is predicted as human-written by our model. This should inspire confidence in our model's accuracy: our false positive rate is very good on scientific abstracts, so every positive prediction made in 2023 and 2024 we can be confident is a true positive.
What we see since then is highly concerning. There have been 3 conference cycles since ChatGPT was launched in November 2022.
The first cycle happened right around the launch of ChatGPT (ICLR 2023). The submission deadline actually was before the launch of ChatGPT, but authors have an opportunity to make edits before the conference itself happened, which was a couple months after the launch of ChatGPT. What we find is expected: only a handful of abstracts are AI-written (we only found 2 out of several thousand to be AI-written in this cycle) and were likely modified after the deadline.
The second cycle was about 6 months later, NeuRIPS 2023, which had a deadline in the summer of 2023 for a December conference. In this conference, we report that about 1.3% of abstracts submitted were AI-generated: a small but significant fraction.
Finally, in the most recent cycle, ICLR 2024, which just happened a few months ago, we noticed an uptick all the way up to 4.9%: an almost 4x growth in AI-generated reviews from NeuRIPS 2023!
These results illuminate a concerning trend: not only is the number of AI-generated conference papers submitted to major AI venues growing, but the number is growing at an increasing rate as well: in other words, the pace at which AI-generated papers are being submitted is accelerating.
What do AI-generated abstracts look like?
Take a look at some of these abstracts and see for yourself if they sound like the kind of writing you are used to reading in technical scientific literature:
-
In the complex landscape of networked data, understanding the causal effects of interventions is a critical challenge with implications across various domains. Graph Neural Networks (GNNs) have emerged as a powerful tool for capturing complex dependencies, yet the potential of geometric deep learning for GNN-based network causal inference remains underexplored. This work makes three key contributions to bridge this gap. First, we establish a theoretical connection between graph curvature and causal inference, revealing that negative curvatures pose challenges in identifying causal effects. Second, based on this theoretical insight, we present computational results using Ricci curvature to predict the reliability of causal effect estimations, empirically demonstrating that positive curvature regions yield more accurate estimations. Lastly, we propose a method using Ricci flow to improve treatment effect estimation on networked data, showing superior performance by reducing error through flattening the edges in the network. Our findings open new avenues for leveraging geometry in causal effect estimation, offering insights and tools that enhance the performance of GNNs in causal inference tasks.
-
In the realm of language models, data encoding is pivotal, influencing efficiency and effectiveness of model training. Byte Pair Encoding (BPE) is a well-established subword tokenization technique that balances computational efficiency and linguistic expressiveness by merging frequent byte or character pairs. As language model training requires substantial computational resources, we propose Fusion Token, a method that substantially enhances the conventional Byte Pair Encoding (BPE) approach in data encoding for language models. Fusion Token employs a more aggressive computational strategy compared to BPE, expanding the token groups from bi-grams to 10-grams. Remarkably, with the addition of 1024 tokens to the vocabulary, the compression rate significantly surpasses that of a regular BPE tokenizer with a vocabulary of one million. Overall, the Fusion Token method leads to noticeable performance improvements due to an increased data scope per compute unit. Additionally, higher compression results in faster inference times due to fewer tokens per given string. By devoting more compute resources to the tokenizer building process, Fusion Token maximizes the potential of language models as efficient data compression engines, enabling more effective language modeling systems.
-
In the rapidly advancing domain of motion generation, enhancing textual semantics has been recognized as a highly promising strategy for producing more accurate and realistic motions. However, current techniques frequently depend on extensive language models to refine text descriptions, without guaranteeing precise alignment between textual and motion data. This misalignment often leads to suboptimal motion generation, limiting the potential of these methods. To address this issue, we introduce a novel framework called SemanticBoost, which aims to bridge the gap between textual and motion data. Our innovative solution integrates supplementary semantic information derived from the motion data itself, along with a dedicated denoise network, to guarantee semantic coherence and elevate the overall quality of motion generation. Through extensive experiments and evaluations, we demonstrate that SemanticBoost significantly outperforms existing methods in terms of motion quality, alignment, and realism. Moreover, our findings emphasize the potential of leveraging semantic cues from motion data, opening new avenues for more intuitive and diverse motion generation.
Notice any patterns? First, we see that they all start with very similar phrases: "In the complex landscape of," "In the realm of", "In the rapidly advancing domain of". We call this artificially flowery language. We've written before about how often LLMs use a lot of words to produce very little actual content. While this may be desirable for a student trying to hit a minimum word count in a homework assignment, for a technical reader trying to consume research, this kind of overly verbose language makes the paper harder and more time-consuming to read, while only making the actual messaging of the paper less clear.
Do AI papers actually get accepted in to the conferences?
We wondered if AI-generated papers are actually effectively filtered out by the peer review process, or if some of them slip through the cracks.
To answer this question, we analyzed the correlation between AI-generated abstracts and paper decisions at ICLR 2024. (Oral, spotlight, and poster all are "Accepted" papers; oral and spotlight are special recognition categories). Here's what we found:
| Category | AI-generated Percentage |
|---|---|
| ICLR 2024 oral | 2.33% |
| ICLR 2024 poster | 2.71% |
| ICLR 2024 spotlight | 1.36% |
| Rejected | 5.42% |
While the percentage of AI-generated papers that were accepted is lower than the percentage submitted, a significant number still made it through the peer review process. This implies that while reviewers may be catching some AI-generated content, they are not catching all of it.
We notice that even some orals and spotlight papers have AI-generated abstracts! Charitably interpreting the situation, what we may find going forward is that the research may actually be high quality, and the authors are simply taking shortcuts with ChatGPT to help them better present or revise the work.
Notably, as much of the research community are not native English speakers, an increasing use of LLMs will be to translate papers written in other languages into English.
Conclusion
Despite the AI community's explicit ask of authors not to use ChatGPT, many authors are ignoring the policy and using LLMs to help them write their papers anyway. More concerning, even AI experts, serving as peer reviewers to guard the conferences against LLM-generated papers, are not able to catch it!
ChatGPT is having even further ripple effects throughout the academic process. A recent ICML case study found that between 6 and 16 percent of the peer reviews themselves were generated by AI, and there is a positive correlation between AI generated peer reviews and how close the review was submitted to the deadline!
We call on the AI community to enforce these policies better and authors to take responsibility to make sure their papers are human-generated.
AI's incursion into formal writing isn't limited to research — AI is also winning fiction prizes.

Bradley is an AI researcher and expert in building deep learning products in industry. He recently led the deep learning research group at Absci, a generative AI drug discovery company, and previously was a member of the core computer vision team at Tesla Autopilot.
While a graduate student, Bradley authored multiple publications in deep learning research with the Stanford Vision Lab. He holds a B.S. in physics and an M.S. in artificial intelligence from Stanford. Aside from AI, he is also excited about education, philosophy, and is an avid golfer.
Related reading

Third-Party Pangram Evaluations
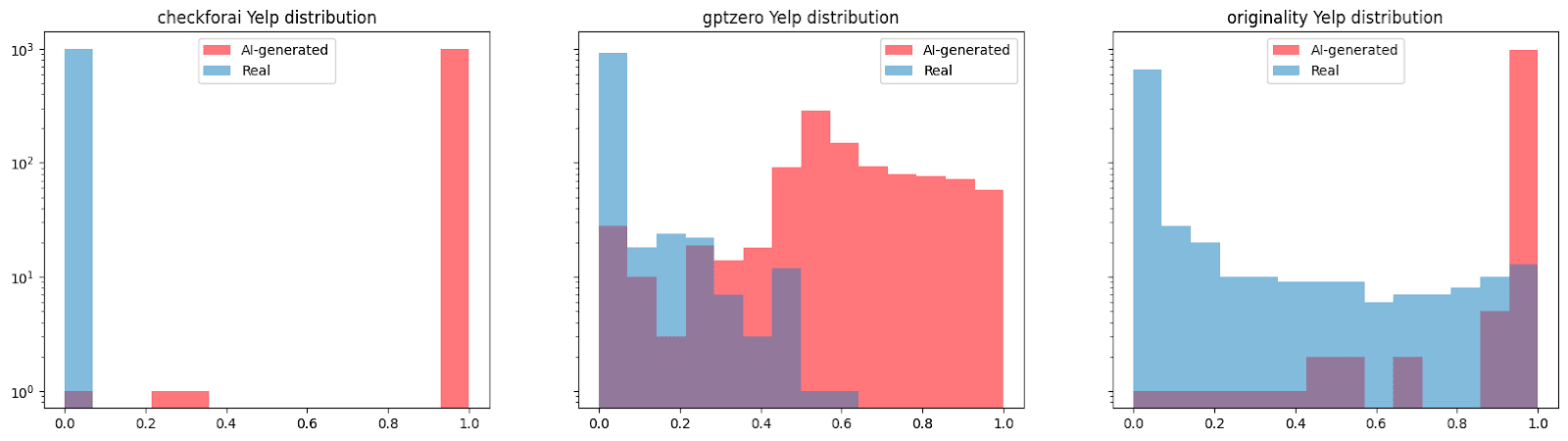
Deep Dive on Yelp reviews
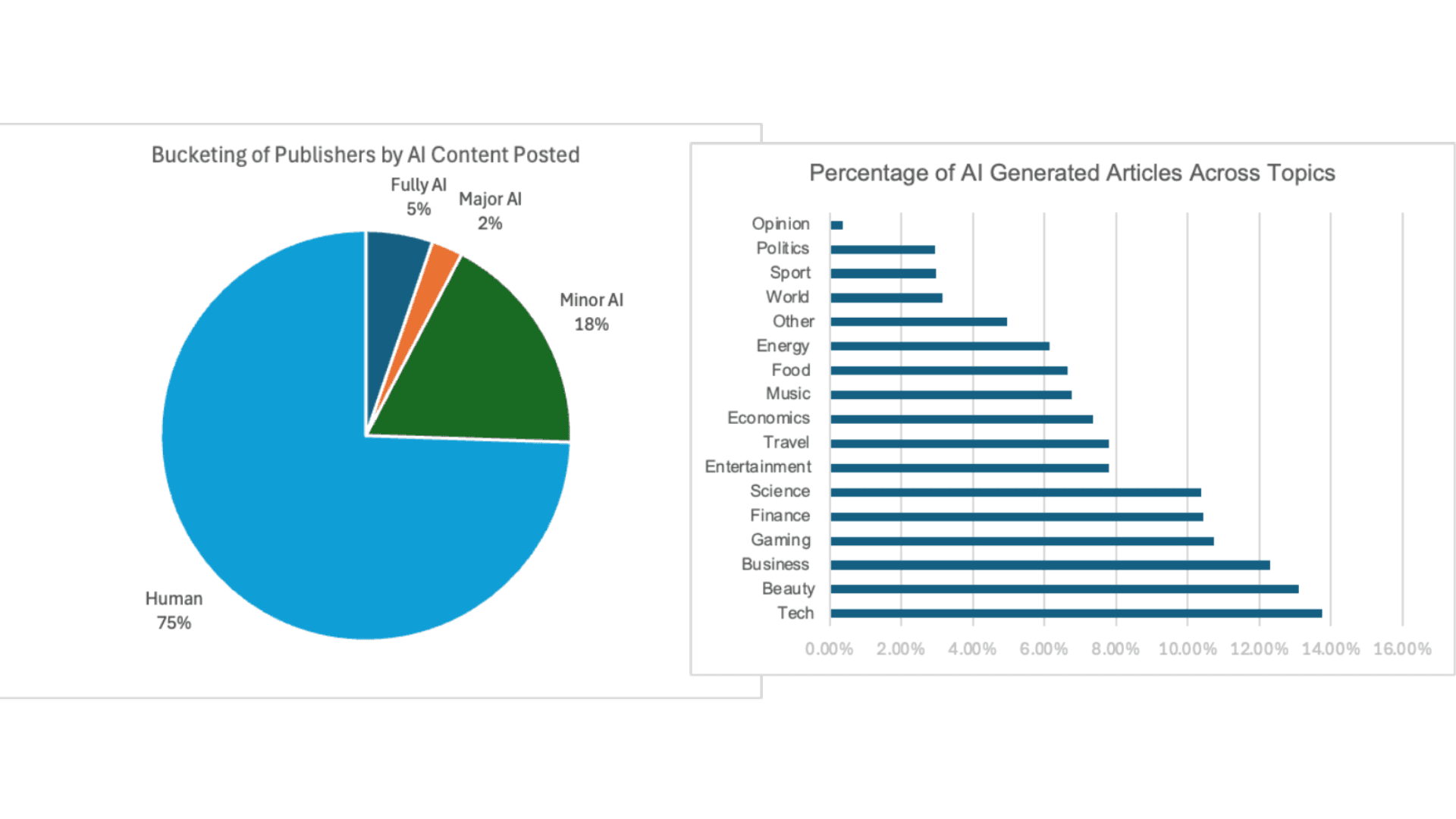
60,000 AI-generated news articles are published every day
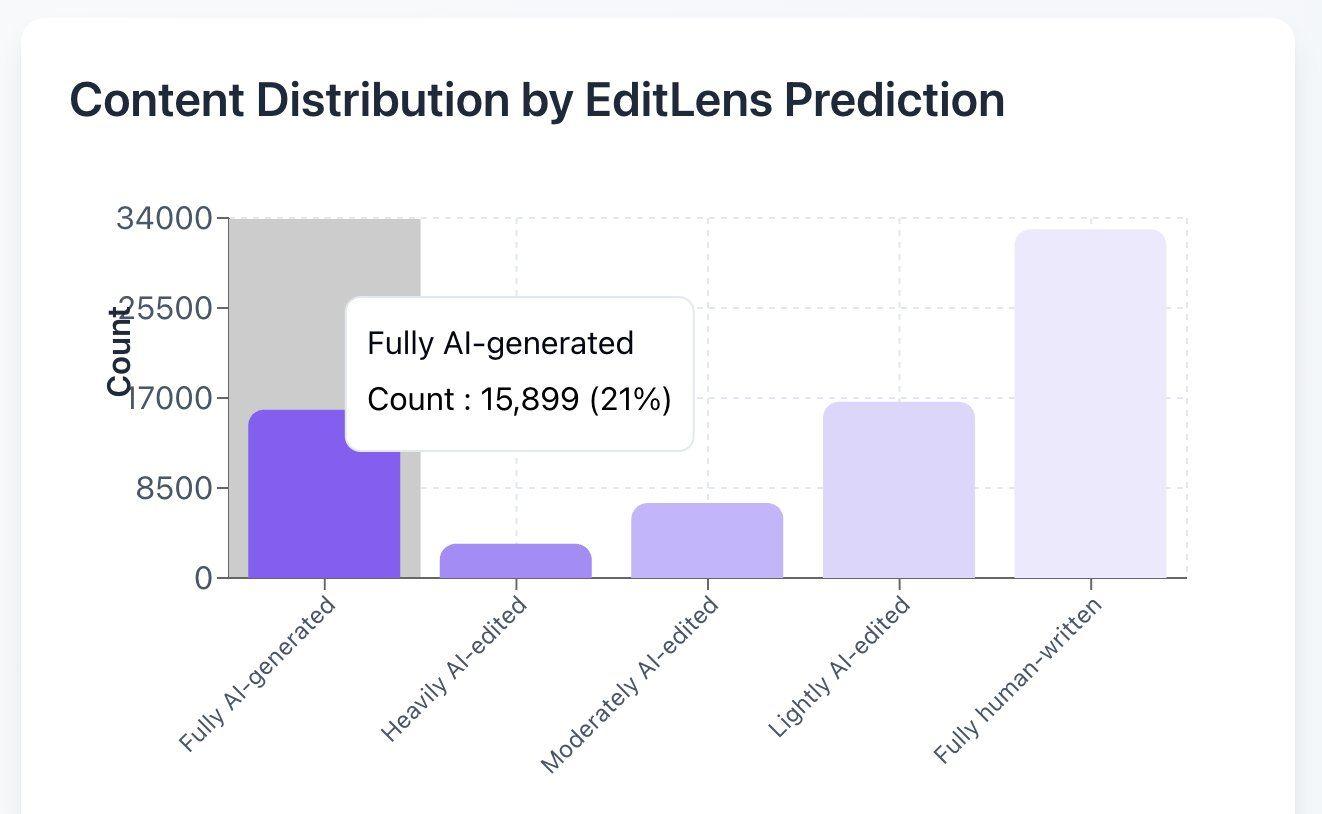
Pangram Predicts 21% of ICLR Reviews are AI-Generated

How to spot AI reviews

AI is Writing Prize-Winning Fiction
to our updates
